Game of Thrones Topic Modeling
In this post, I use unsupervised learning to identify the topics in pages from the Game of Thrones books. I use Python and an off-the-shelf implementation of the Latent Dirichlet Allocation (LDA) in AWS SageMaker. I wont pretend to understand the complicated stats behind LDA here. This post is about data preparation, SageMaker, natural language processing (NLP), and data visualization. All the code I wrote for this project can be found on my GitHub.
Topic Modeling with LDA
Topic modeling is the practice of automatically categorizing large unstructured corpuses. One set of topic modeling algorithms use unsupervised learning. In unsupervised learning, the data going into the training is not labeled. One such algorithm is called LDA.
LDA uses “bag-of-words” to represent documents. In bag of words, grammar and word-order of documents is not preserved. Documents are represented n-dimensional vectors where n is the number of words in the vocabulary. For example, suppose the only two documents in your corpus are:
- “Humpty Dumpty sat on a wall”
- “Humpty Dumpty had a great fall”
Your vocabulary would then be the array:
['humpty', 'dumpty', 'sat', 'on', 'a', 'wall', 'had', 'great', 'fall']
and the documents above would be represented as the vectors:
[1, 1, 1, 1, 1, 1, 0, 0, 0]
[1, 1, 0, 0, 1, 0, 1, 1, 1]
LDA uses these bag-of-words documents to learn topics in your corpus. Topics are defined as probabilities over your vocabulary. For example, you might build a topic model with a set of news articles. The topics it would spit out could look something like this:
| topic 1 | topic 2 | topic 3 |
|---|---|---|
| 50% - trump | 60% - football | 65% - brexit |
| 40% - election | 50% - patriots | 50% - europe |
| 40% - mueller | 50% - yards | 45% - parliment |
| 3% - football | 5% - trump | 7% - trump |
| … | … | … |
Why Game of Thrones?
Game of Thrones follows several characters’ journeys through the fantasy land of Westeros. The book is written in a way such that each chapter pertains to a specific character’s storyline. For example, the first chapter of book 1 starts the story of Bran while the second chapter is all about Catelyn. Each character has their own storyline and environment, meaning the content of all the Bran chapters is quite different from the content of all the Catelyn chapters.
The hope is that LDA comes up with topics that mirror the characters’ environments. For example, I would hope to see a topic with high probabilities in the words “snow”, “wall”, “ghost”, etc and a second chapter with high probabilities in the words “dragon”, “fire”, “drogo”, etc. As a reader, I know those words relate to specific characters. Remember that all the LDA algorithm will receive is loose “pages” without any information about the book or chapter they came from.
Reading EPUB Files and NLP Pre-processing
First, the dirty business of dealing with training data coming from ebooks. I wrote a script which processes epub books into documents of tokens and a vocabulary. The preprocessing steps at a high level are:
- Read the epub file into a string (HTML encoded)
- Find the chapter boundaries in the epub content
- For each chapter, process it’s contents into tokens (stemming, removing stopwords, non-ascii words, words shorter than 3 letters)
- Break each chapter into documents of 250 tokens
- Write the documents to disc as text files
As example, here is the first few sentences of Book 1 as raw epub text:
<p class="center"><img alt="" src="../Images/Mart_9780553897845_epub_L03_r1.jpg"/></p>
<h1 class="chapter0" id="c01"><a id="page1"/><strong>PROLOGUE</strong></h1>
<p class="nonindent"><span class="dropcaps">“W</span>e should start back,” Gared urged as the woods began to grow dark around them.</p>
<p class="indent">“The wildlings are dead.”</p>
Step 3 of the process above would turn the above text into the following token list:
['prologu', 'start', 'back', 'gare', 'urg', 'wood', 'began', 'grow', 'dark', 'around', 'wildl', 'dead']
During the pre-processing, you also need to build up the vocabulary for your project. The vocabulary is a list of all unique tokens found in your corpus. Papers and blogs also recommend further preprocessing of the final vocabulary for LDA training. I removed all words from the vocabulary that appeared in over half the documents as well as words that appeared in less than 15 documents.
I wrote a script which takes care of all of the preprocessing detailed here. In processing the 5 Game of Thrones books, I ended up with 358 chapters containing 3249 pages. The resulting vocabulary was 4191 words long.
Training
AWS SageMaker offers an off-the-shelf LDA training image. The image requires training data to be put in S3 in a specific format, but it is pretty much plug-and-play besides that. Training can be broken down into a few steps:
- Load the vocabulary and documents defined in the preprocessing steps
- Convert the documents into term-count vectors (each document is represented as a vector the length of the vocabulary)
- Convert the term-count vectors into numpy arrays and then into recordio format used by the LDA algorithm
- Upload the training data to S3
- Use the LDA training image from SageMaker and kick off a training job
- Inspect the topics learned by the training job
My full training script can be found here.
The most interesting step in training is step (5) above.
This is done by creating a SageMaker estimator, setting the hyperparameters, and calling fit which kicks off the training job.
Here is a code snippet showing that process.
from sagemaker.amazon.common import numpy_to_record_serializer
from sagemaker.amazon.amazon_estimator import get_image_uri
session = sagemaker.Session()
region_name = boto3.Session().region_name
container = get_image_uri(region_name, 'lda')
# convert documets to recordio format
recordio_protobuf_serializer = numpy_to_record_serializer()
train_recordio = recordio_protobuf_serializer(train_doc_term_counts)
# upload to S3 in bucket/prefix/train
s3_object = os.path.join('LDA-testing', 'train', 'lda_training.data')
boto3.Session().resource('s3').Bucket('alex-sm').Object(s3_object).upload_fileobj(train_recordio)
s3_train_data = 's3://{}/{}'.format(bucket, s3_object)
lda = sagemaker.estimator.Estimator(
container,
role,
output_path='s3://{}/{}/output'.format(bucket, prefix),
train_instance_count=1,
train_instance_type='ml.m5.large',
sagemaker_session=session,
)
# set algorithm-specific hyperparameters
lda.set_hyperparameters(
num_topics=10,
feature_dim=len(vocab),
mini_batch_size=len(documents),
alpha0=1.0,
)
# run the training job on input data stored in S3
lda.fit({'train': s3_train_data})
I chose to set 10 as the number of topics because there are roughly 10 main characters in GoT.
Once the fit call is made, the training job will show up in the SageMaker console.
Once the training is done, the resulting topics can be inspected. This portion wasn’t really documented by AWS, but the data is in there! With a bit of data fandangling, I was able to display the learned topics by showing the words with highest probabilities in each.
| topic 0 | topic 1 | topic 2 | topic 3 | topic 4 |
|---|---|---|---|---|
| arya : 0.014 | stanni : 0.012 | ladi : 0.015 | sansa : 0.020 | tyrion : 0.034 |
| sword : 0.006 | davo : 0.007 | knight : 0.010 | arya : 0.014 | father : 0.009 |
| face : 0.006 | wall : 0.007 | catelyn : 0.010 | ladi : 0.013 | want : 0.006 |
| want : 0.006 | black : 0.007 | father : 0.009 | queen : 0.009 | lannist : 0.006 |
| jaim : 0.006 | knight : 0.007 | jaim : 0.008 | joffrey : 0.008 | face : 0.006 |
| head : 0.005 | brother : 0.006 | call : 0.007 | father : 0.008 | might : 0.005 |
| topic 5 | topic 6 | topic 7 | topic 8 | topic 9 |
|---|---|---|---|---|
| dani : 0.021 | theon : 0.014 | bran : 0.050 | jaim : 0.035 | stark : 0.299 |
| dragon : 0.014 | bastard : 0.013 | hodor : 0.026 | cersei : 0.032 | winterfel : 0.275 |
| queen : 0.009 | father : 0.011 | maester : 0.011 | lannist : 0.022 | rise : 0.234 |
| blood : 0.008 | keep : 0.010 | robb : 0.010 | queen : 0.020 | catelyn : 0.031 |
| jorah : 0.006 | want : 0.010 | meera : 0.010 | realm : 0.016 | robb : 0.028 |
| grace : 0.006 | snow : 0.009 | jojen : 0.010 | grace : 0.013 | lannist : 0.022 |
Remember! These topics were learned in an unsupervised way, the algorithm had no infromation about which pages came from which chapters. Anyone familiar with the series will see that the words in each topic make a lot of sense together. Topic 5 for example is clearly words related to Daenerys’ storyline while topic 7 is made up of words related to Bran.
Inference
But what can we do with this topic model? For one, we can use figure out what the topic makeup of each of our documents is. SageMaker offers an easy way to put up an inference endpoint using the model we trained earlier. We can then run our documents through in batches and delete the endpoint when we’re done. Inference on each document will return a vector of length 10 (the number of topics).
training_job_name = "lda-training-job-name"
lda_inference = deploy_endpoint(training_job_name)
def chunker(seq, size):
return (seq[pos:pos + size] for pos in range(0, len(seq), size))
for doc_batch in chunker(documents, batchSize):
raw_batch_results = lda_inference.predict(np.array(doc_batch))
for prediction in raw_batch_results['predictions']:
print(prediction['topic_mixture'])
sagemaker.Session().delete_endpoint(lda_inference.endpoint)
As an example, if I take one of the documents that came from an Arya chapter, the topic mixture I get back makes sense! Most heavily weighted are the topics related to Arya (topics 0 and 3 above)
[0.52085709, 0.0, 0.0, 0.45601841, 0.0, 0.0, 0.0, 0.0231244862, 0.0, 0.0]
Contrast that with the topic mixture for a random document from a Bran chapter:
[0.122665308, 0.0, 0.0, 0.0, 0.0167210493, 0.0, 0.0, 0.86061370, 0.0, 0.0]
And the results still look promising! My full inference script can be found here.
Analysis
Now that we have all of our documents (pages from GoT books) represented as 10-dimensional vectors, we can see if the topic model is really acting as expected. Because of the way Game of Thrones is written, we would expect documents that originated from the same characters’ chapters to have similar topic vectors.
One fun way to visualize this data is with a graph database! We can use the documents as vertices and the edge weights between documents can be defined as the similarity between the documents’ topic vectors. One way to measure similarity between topic vectors is to take the eucledian distance between them.
If we take the eucledian distance between all documents, we would get a fully connected graph with over 10 million edges. Since I was doing the graph processing on my laptop, I had to cut things down a bit. I decided to only take the top few thousand most “heavy” edges, meaning edges linking the most similar documents. I used Gephi, an open source graph visualization tool and used the OpenOrd algorithm to visualize the node layout in my graph. OpenOrd expects undirected weighted graphs and aims to better distinguish clusters, which is exactly what I required.
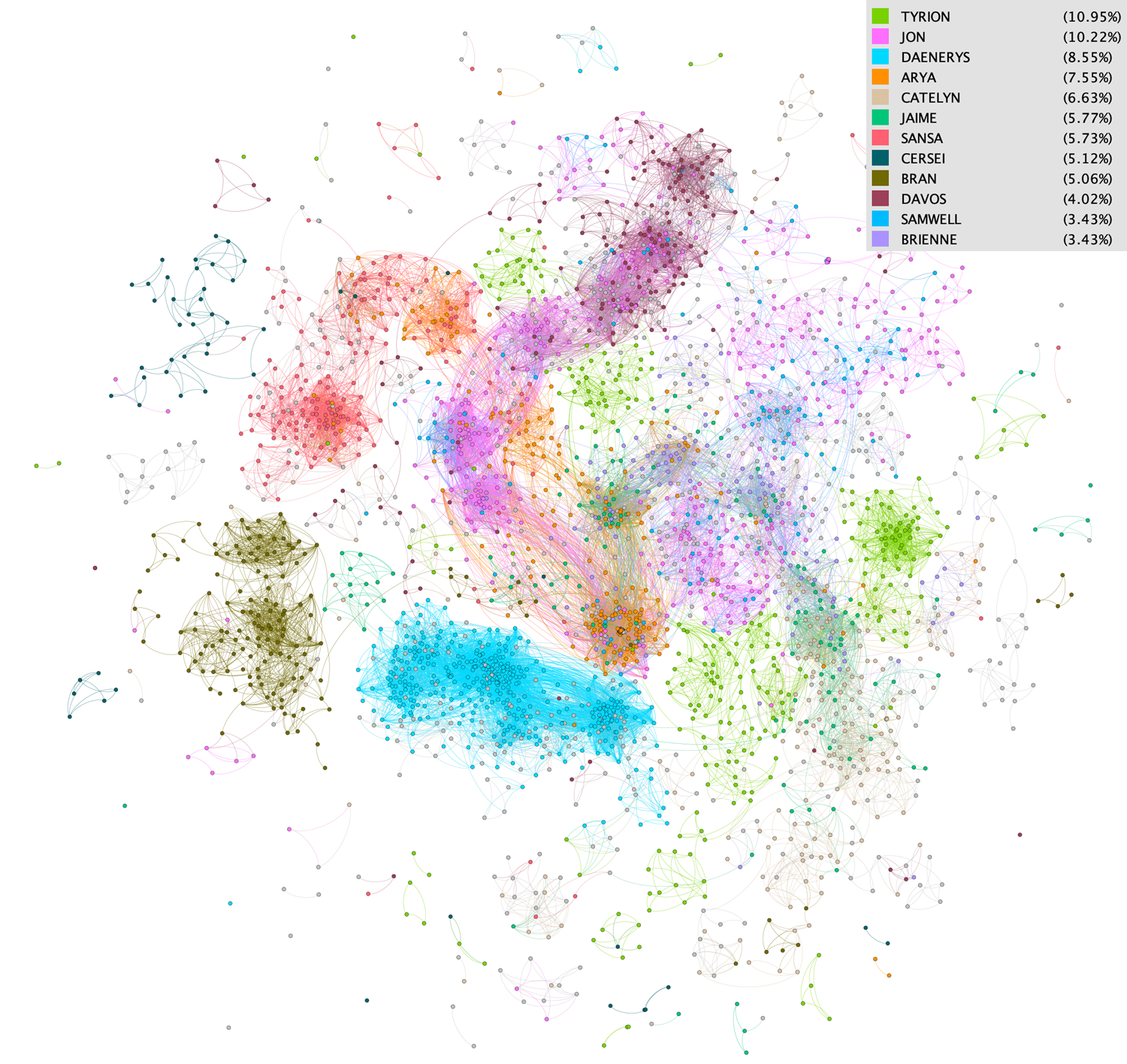
By throwing a color on each node depending on the character who’s chapter the document came from, we can see that pages from the same characters are indeed clustering together!
Thoughts
My goal in this project was to try out LDA topic modeling with a novel dataset. AWS SageMaker made the process fairly painless. I also tried using Databricks and Azure off-the-shelf algorithms for this project but found AWS to be far easier to use. Once the text was properly processed and Gephi provided fun visualization.
Since Game of Thrones is written with such distinct storylines separated by chapters, we have an idea of what topics should be spit out by an unsupervised learning algorithm. I trained the model, ran the inference, and visualized the output to show that the learned topics line up with the characters in the books as expected!