Am I a Devops Person Now?
I’ve considered myself a full stack developer for some time now. To me, that always meant “I write code that runs on the client and the server.” AWS CDK has made me rethink that.
CDK is “an open source software development framework to define your cloud application resources using familiar programming languages.” In other words, I can write Python to define my AWS resources and how they talk to each other. I’ve had the opportunity over the last few months to learn and use CDK at work. We have even deployed a production ETL pipeline and several other stacks using it. So now, in addition to writing code that run on the client and the server, I can write code that defines the entire backend!
All the code I wrote for this project can be found on my GitHub.
Example: Image ETL Pipeline
For this blog, I wanted to come up with an example that would involve a few AWS resources I haven’t used before. Also, since I work a lot with computer vision projects, I wanted something to do with images. I decided to built a simple image ETL pipeline. Raw images are uploaded to S3, resized into several sizes, and stored back in S3. Further, records of the images are stored in a database. The example is a bit contrived, but seems like a fair simplified representation of what I might build as an ML engineer.
First, a tiny bit of vocabulary. In CDK, you build an app. An app is made up of one or more stacks. How to separate an app into stacks is up to the developer. The pattern I use myself is to separate parts of the application depending on how often they might change, as well as their purpose. For example, I like to separate out the VPC into its own stack if its anything more complicated than the default VPC. I also like to keep the database in its own stack. Beyond that, it really depends on the application.
In this case, I built one stack that handles all the image processing. I support that with two smaller stacks that facilitate an web page and API for uploading raw images to S3.
Image Processing Stack
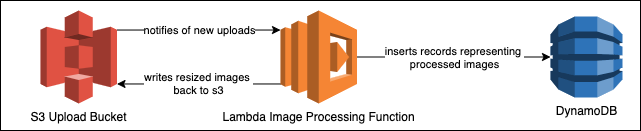
The actual ETL process of this application is the image processing stack. The stack consists of:
- An upload s3 bucket and prefix
- A lambda function triggered when new uploads arrive and processes images
- A DynamoDB table where information about images is stored
In writing this stack, I ran into an issue with Lambda I hadn’t had before. When I deployed my lambda function initially, the PIL package was failing on import. The issue was that I was building PIL on my mac and copying that to Lambda which is a Linux environment (related SO post).
It turns out there is a PythonLayerVersion class in CDK that solves just this problem.
That class takes a path to a directory containing a requirements.txt file as a constructor param.
Upon deploy, CDK installs all dependencies listed in the requirements within a linux docker image and uploads the output as a lambda layer.
The only downside is that it requires the host to have docker installed, though I can’t say that is a high bar.
from aws_cdk import aws_lambda
from aws_cdk import aws_lambda_python
image_processing_lambda = aws_lambda.Function(
self, "image-processing-lambda",
function_name="image-processing-lambda",
runtime=aws_lambda.Runtime.PYTHON_3_8,
code=aws_lambda.Code.asset('path/to/my/lambda'),
handler='image_processor.handler',
layers=[aws_lambda_python.PythonLayerVersion(
self,
"image-processing-lambda-layer",
entry="path/to/dir/with/requirements/file",
compatible_runtimes=[aws_lambda.Runtime.PYTHON_3_8]
)]
)
Otherwise, the resources used in this stack are pretty well documented and easy to use. I had never used DyanmoDB before this so that was a fun learning opportunity for me. I’m still reading and learning but it is extremely scalable and easy to use for simple use cases like this.
I won’t go over all the details of the stack, but the full code is on my GitHub.
With the Lambda, Bucket, trigger, and a few other things defined, a cdk deploy will launch all of that into the cloud.
It’s lovely to navigate the AWS console and watch the resources I used to painstakingly deploy via CLI or the browser pop into existence.
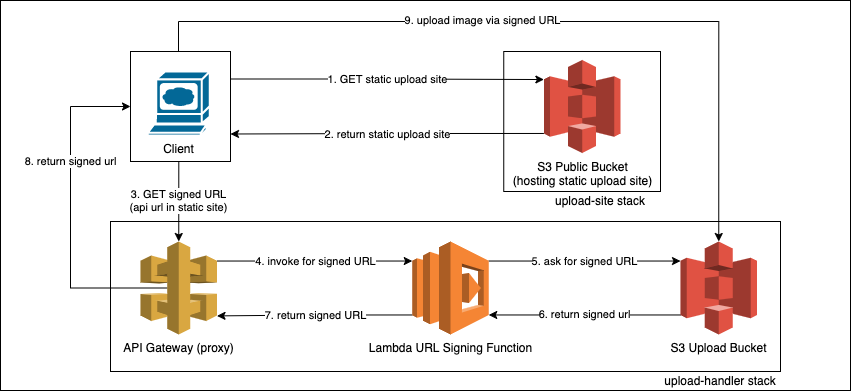
Upload Stacks
The second and third stack in this application provide a way to upload images to S3.
This was my opportunity to use CDK’s RestApi and BucketDeployment class.
The upload-site stack simply hosts the static site a user navigates to to upload an image.
The upload-handler stack has all the resources needed to allow a client to upload an image to a non-public s3 bucket.
I have detailed how the client interacts with both stacks to complete an upload in the diagram below.
One big hangup I ran into with these stacks was passing the API endpoint url from the upload-handler stack to the upload-site stack.
The issue is that the API url is passed from one stack to another as a token, rather than the actual dynamic url.
I’ve opened an issue on the CDK repo about this.
In any case, the solution for now is to get the API endpoint from the upload-handler stack after it is deployed, paste it in the upload-site stack code and redeploy upload-site.
It isn’t a great solution by any means, but it works.
A piece of code I want to highlight here is how easy it was to deploy a static site on S3 using CDK.
All it takes is two constructor calls and a path to the code you want to deploy (a dir static_upload_site in this case).
from aws_cdk import core
from aws_cdk import aws_s3_deployment
from aws_cdk import aws_s3
class UploadSite(core.Stack):
def __init__(self, scope: core.Construct, construct_id: str) -> None:
super().__init__(scope, construct_id)
public_bucket = aws_s3.Bucket(self,
'public_bucket',
public_read_access=True,
website_index_document='index.html')
static_upload_site = aws_s3_deployment.BucketDeployment(
self,
"deployStaticWebsite",
sources=[aws_s3_deployment.Source.asset("static_upload_site")],
destination_bucket=public_bucket
)
Thoughts
AWS CDK continues to blow me away. The biggest value this tool brings is the ability to bring devops into all the same processes as software development. Stacks can be subject to code reviews, changes tracked via source control, collaborated upon, reproduced easily, audited, iterated upon, everything. Further, the fact that it support Python and JavaScript makes it so comfortable for software devs like me to work with.
There is something special about pushing one button, cdk deploy in this case, and having a whole backend deployed as well as everything running on it.
It’s also immensely satisfying to have all the code related to a project in one place.
You have code defining permissions of a lambda function, and one directory over you have the code that runs in the lambda function, and so on.
I still have questions about how this framework scales to larger projects that involve more than a couple developers. I am also curious about what sorts of testing options might be available beyond something like moto. Despite that, CDK is by far the strongest devops tool I’ve had the chance to use.